Semantic Drift in Machine Learning
Machine Learning models are static artefacts based on historical data, which start consuming consuming “real-world” data when deployed into production. Real-world data might not reflected the historical training data and test data, the progressive changes between training data and “real-world” are called the drift and it can be one of the reasons model accuracy decreases over time.
How can drift occur?
- Sudden: A new concept occurs within a short time.
- Gradual: A new concept gradually replaces an old one over a period of time.
- Incremental: An old concept incrementally changes to a new concept.
- Reoccurring: An old concept may reoccur after some time.
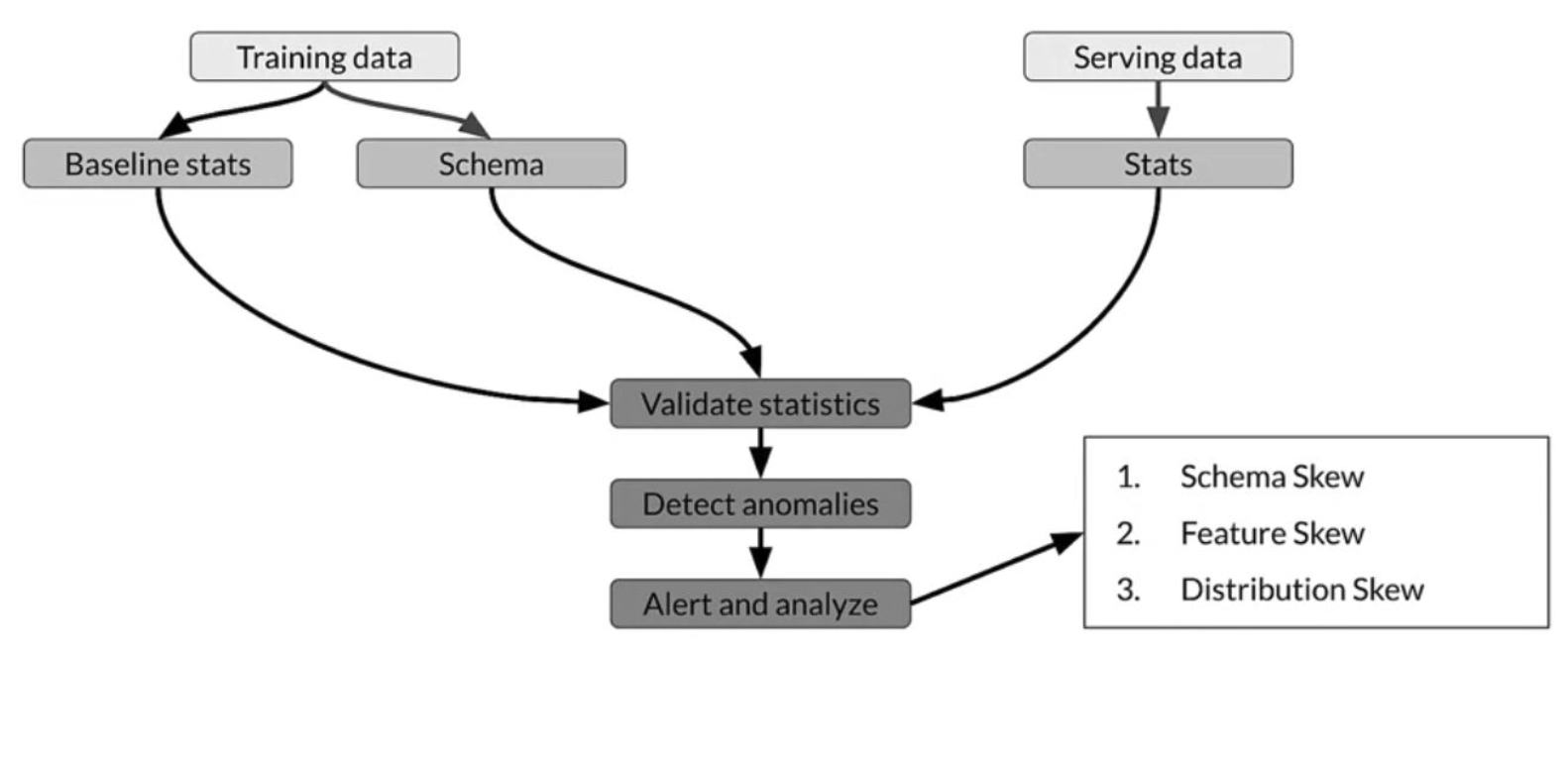
Drift detection in a nutshell
1) Create two datasets: reference and current/serving
2) Calculate statistical measures for features values in the reference (e.g.: distribution of values over features)
3) The reference dataset act as the benchmark/baseline
4) Select “real-world” data - current/serving
5) Calculate the same statistical measures as for the reference
6) Compare them both using statistical tools (e.g.: distance metrics, test hypothesis)
7) Depending on a threshold assume or not drift occurred
NOTE: repeat steps 4 to 6 periodically
Drift, Skew, Shift
• Data Drift: changes in the statistical properties of features over time, due seasonality, trends or unexpected events.
• Concept Drift: changes in the statistical properties of the labels over time, e.g.: mapping to labels in training remains static while changes in real-world.
• Schema Skew: training and service data do not conform to the same schema, e.g.: getting an integer when expecting a float, empty string vs None.
• Distribution Skew: divergence between training and serving datasets, e.g.: dataset shift caused by covariate/concept shift.
Covariate Shift
Marginal distribution of features \(x\) is not the same during training and serving, but the conditional distribution remains unchanged.
Example: number of predictions of relevant/non-relevant text samples is in line with development test set, but the distribution of features is different between training.
Concept Shift
Conditional distribution of labels and features are not the same during training and serving, but the marginal distribution features remain unchanged.
Example: although the text samples being crawled did not change and the distribution of features values is still the same, what determines if a text sample is relevant or non-relevant changed.

How to detect them?
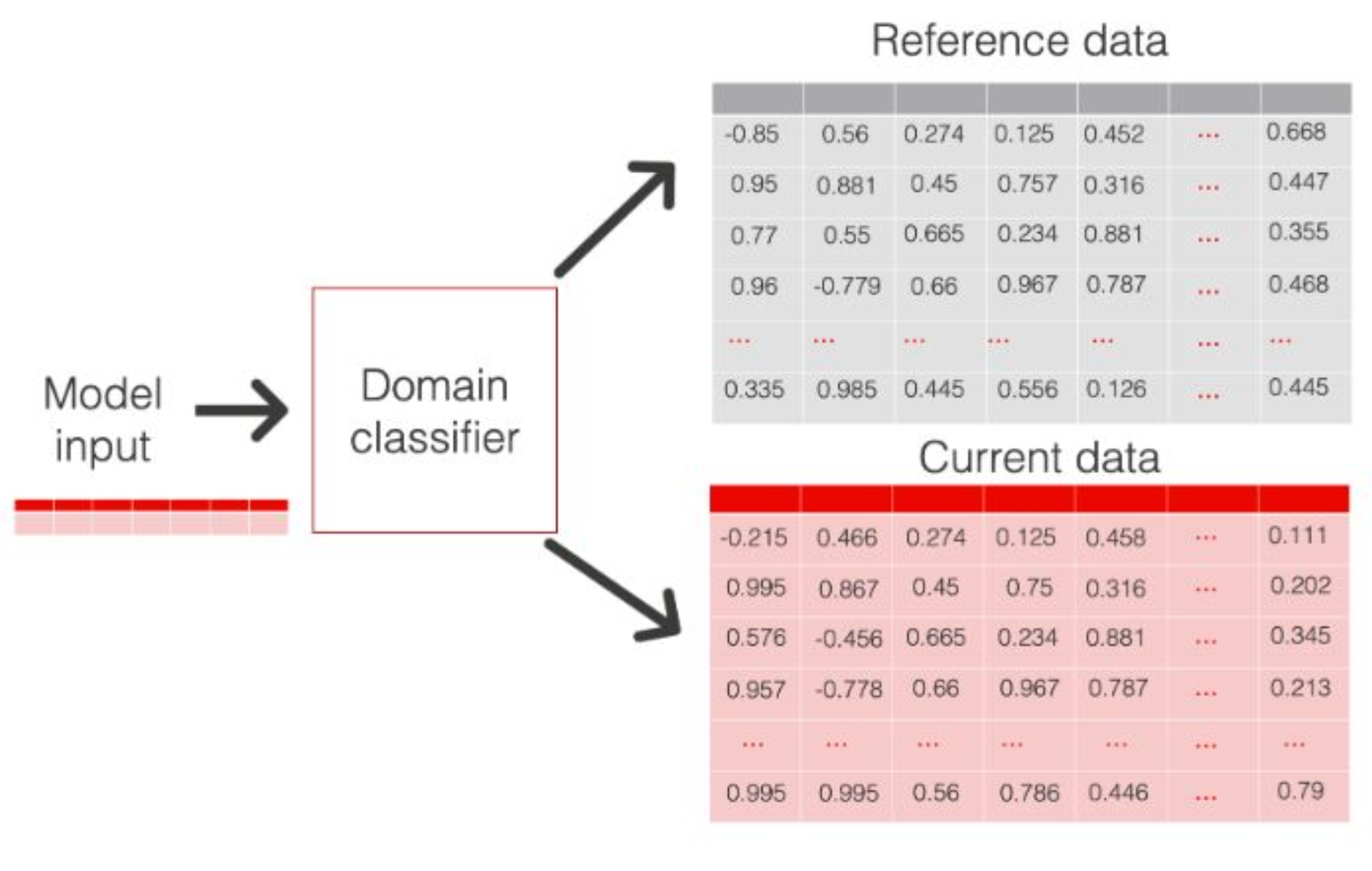
Measuring Embeddings Drift
-
Average the embeddings in the current and reference dataset, compare with some similarity/distance metric: Euclidean distance, Cosine similarity;
-
Train a binary classification to discriminate between reference and current distributions. If the model can confidently identify which embeddings belong to which you can consider the two datasets differ significantly.
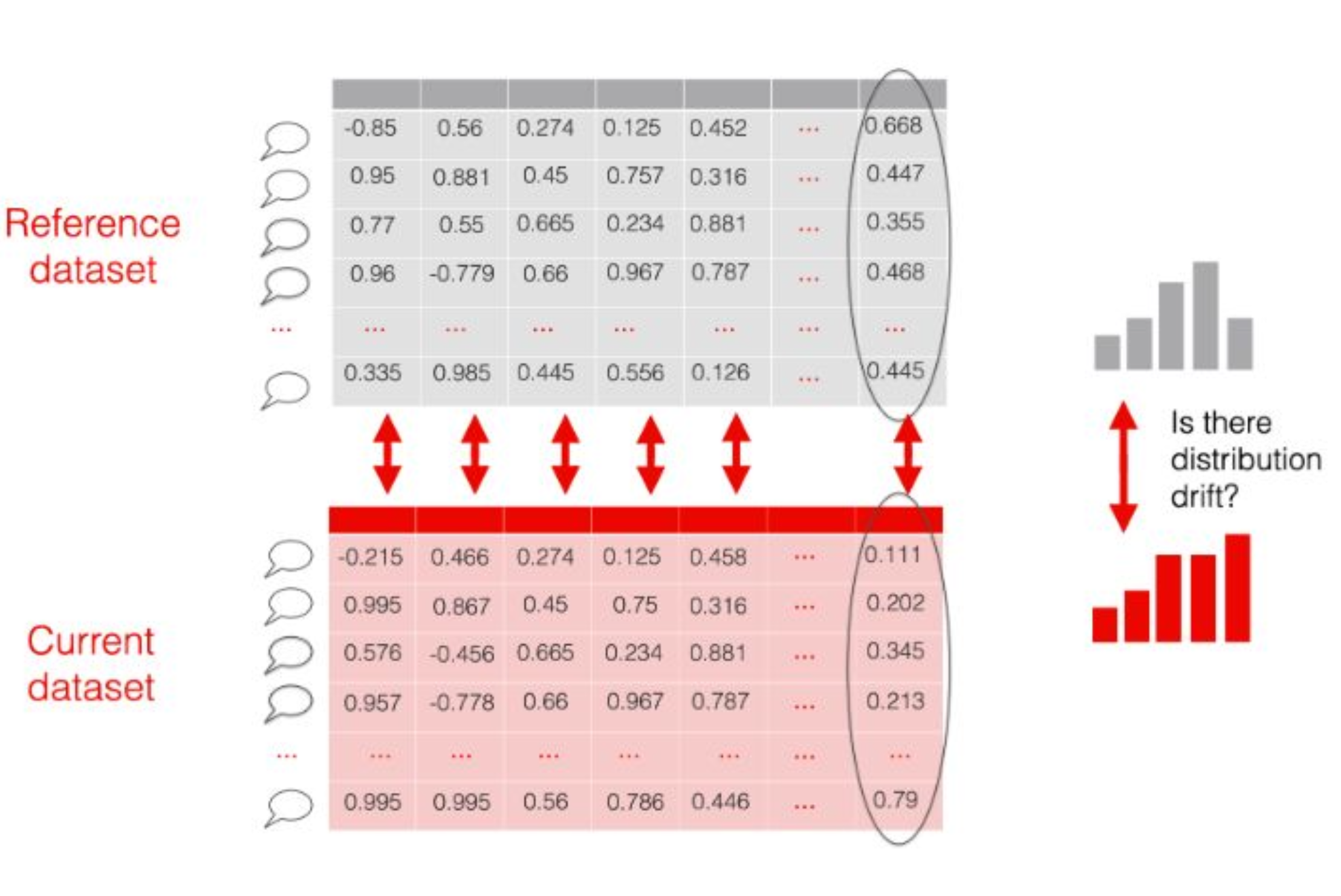
Share of drifted components
-
Embeddings, can be seen as a structured tabular dataset. Rows are individual texts and columns are components of each embedding
-
Treat each component as a numerical “feature” and check for the drift in its distribution between reference and current datasets.
-
If many embedding components drift, you can consider that there is a meaningful change in the data.
References
semantic-drift classification 